
A corpus of storytelling for research on multimodal language use and interactional rapport, comparing three language/cultural groups
We have audio-videotaped spoken narrative discourse elicitations, comprising 32 of Mexican Spanish speakers, 36 of Iraqi Arabic speakers, 9 of Emirati Arabic speakers, and 37 of American English speakers (114 total). Participants in our elicitations were pairs of people with pre-establised rapport (friends, close acquaintances, etc.).
One member of each pair watched the 5 ½-minute Pear film and then was videotaped telling the story of it to the other. These videotaped natural interactions, varying from 2 to 18 minutes in length (averaging about 4-5 minutes), are the foundation of the corpus of transcribed and annotated natural language data on which our study, “Dyadic Rapport within and across Cultures: Multimodal Assessment in Human-Human and Human-Computer Interaction”, is primarily based.
In this area of our website, we describe how we (i) recorded these data, (ii) transcribed the speech from the three languages using the software interface Praat (link here) and employing the Linguistic Data Consortium’s RT-03 annotation guidelines (link here), (iii) developed and applied a computer-automated transcoding process to transliterate Arabic orthographic text into a Latin character written form, (iv) automatedly generated word-by-word transcriptions from phrase transcriptions using the force alignment software SONIC (link here), (v) translated the Arabic and Spanish phrases into idiomatic English, (vi) added English word glosses, and finally, (vii) employed SONIC again to generate a phone-level segmentation of the speech signal.
The following flowchart maps the processing steps involved in building this corpus by language; click the image for a larger view.
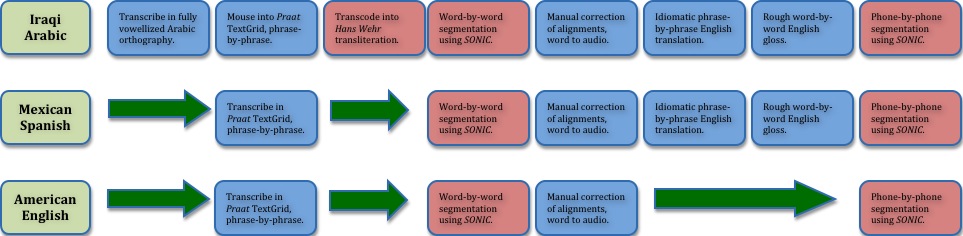
The resulting corpus of multi-tiered Praat TextGrids is currently supporting speech acoustic analyses directed at determining, e.g., speaker prosodic features that cue listener vocal feedback and how these differ across the three languages. We also import the speech transcriptions into the interface ELAN (link here), for further annotation of a variety of nonverbal behaviors that occur during interactive spoken discourse; including, gaze, head nods and tilts, gestures, posture shifts, and facial expressions. The resulting corpus of speech and nonverbal behavioral ‘metadata’ will support planned cross-cultural comparisons of interactional rapport. These will in turn inform efforts to model culturally appropriate behaviors in computer-generated ‘Embodied Conversational Agents’ for use in studies of Human-Computer Interaction at the Institute for Creative Technologies (preview the Rapport Agent here).
next >