
The transcription process differed across the three languages in our corpus, though certain aspects of transcription were common to all three.
Phrase Transcription in Fully Vowelized Arabic OrthographyFor Iraqi Arabic, the first step in the transcription process was to create a .txt file transcript organized by speaker turn. This transcript was created in Basis Technology's Arabic Editor, a Windows-based software that allows the creation of fully vowellized Arabic orthography text using a standard American keyboard (each Arabic character is assigned to a phonetically similar Roman character key). We elected to use this software for ease of mastery by our native speaker transcribers, and for the fact that it did not require any additional hardware or a keyboard visualizer. We considered using RedleX Mellel, an Apple OS-based Arabic orthography text editor which offers similar capabilities. However, use of Windows-based Arabic Editor in the early stages of this effort facilitated collaborative work with our partners in the Middle East where Mac OS is not a commonly used platform.
Praat TextGrids for All Three Languages
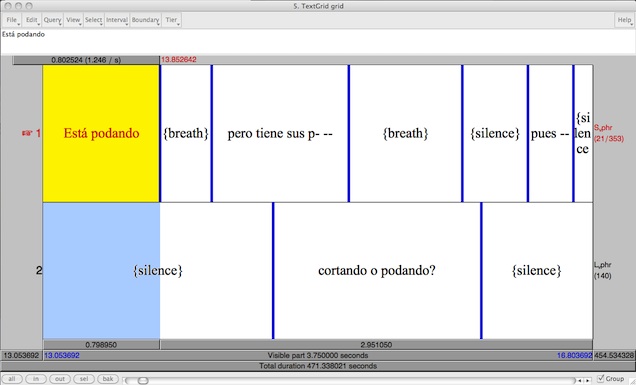
After this initial transcript was created, the Arabic orthography text was manually copied and pasted into time-aligned intervals in a two-tiered Praat TextGrid. For both Mexican Spanish and American English, transcription was performed directly into Praat TextGrid files.
An English TextGrid:
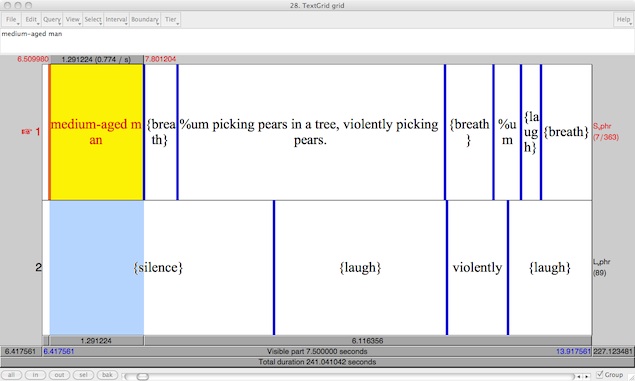
In all three languages, transcribers worked primarily from .wav files with separate channels for the two participants in the elicitation, though the corresponding videos were available to them for difficult intervals of speech. Transcribers in each language also employed the Linguistic Data Consortium's RT-03 transcription conventions for the annotation of nonspeech sounds, filled pauses, word and utterance level speech breaks, and other disfluencies.
< previous next >