
Once the speech is in Praat TextGrid format, it is subject to automated processing; as in other steps, the processes applied to the Arabic differed from those applied to the English and Spanish data.
Arabic Transcoding/TransliterationPrior to word-level forced alignment, Arabic was processed with a transcoding software developed by Dan Parvaz at the MITRE Corporation. The library driving the transcoder (informally dubbed “Danscoder”) is IBM's International Components For Unicode, which includes a complete transliteration engine. ICU includes a small programming language for developing transliteration schemes, which are implemented as a series of cascading finite-state transducers (FSTs).
This transcoder made use of the full vowel information in our transcripts, and output a transliteration time-aligned with the original Arabic orthography, preserving the RT-03 transcription conventions for nonspeech sounds, filled pauses, and word-level and utterance-level speech breaks.
We elected to use the Hans Wehr transliteration system in our corpus for readability, but the transcoder can output to any of a number of industry standard transcription systems, including Buckwalter, ALA-LC, and IPA. The following is an example of a TextGrid with Arabic orthography tiers and corresponding transliteration tiers. Note that the Arabic does not display with the characters properly connected; this is an issue in Praat on Mac OS to which we are giving attention.
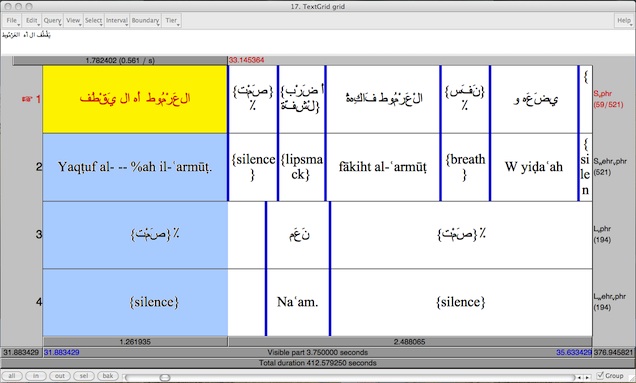
All subsequent automated and human processes applied to Arabic TextGrids were applied to this transliteration tier.
Sonic Forced Alignment SoftwareAll three languages were processed with Sonic (Pellom et al., 2001), a forced alignment software which automatedly segmented phrase-level time aligned Praat TextGrid intervals into word level time-aligned intervals, as in the following English example.

Though developed with reference to English language speech data, Sonic is reasonably language portable. It offers the advantage of adaptation without acoustic model retraining, relying on a pronounciation dictionary and phone list which can be adapted according to language or dialect. For more information about Sonic, visit the Boulder Language Technologies website here.
< previous next >